
Larger than a Million Legitimate-Repeal Uncover Neutrality Comments were Seemingly Faked
Additional Notes:
- There had been some gargantuan analyses infected by the non-textual aspects of the submissions, as an illustration, their timing, the email addresses mature, and other metadata. Bawl out to the work of Jeffrey Fossett, who did a first pass evaluation of the in part submitted feedback in May moreover that impressed this post and among the suggestions mature in the evaluation, to Chris Sinchok, GravWell, and loads other posts I studied in making ready this evaluation.
- Let me know here can take into accout to you might per chance simply take into accout any questions or would cherish entry to the dataset I scraped from the FCC’s ECFS submission machine — if sufficient of us set apart a question to it, I might per chance simply host the dataset on Google BigQuery so that that it is doubtless you’ll speed SQL queries on the ~sixty four GB dataset for your gather.
Footnotes:
¹ I.e., no longer from a spambot or phase of an identified campaign.
² Plump disclosure: I used to be a summer law clerk for Commissioner Clyburn in 2010, and though I vastly bask in her most modern work championing accumulate neutrality, the opinions and POV on this post are my gather.
³ No longer clustered as phase of a comment submission campaign, no longer a reproduction comment.
⁴ Files serene from starting of submissions (April 2017) till Oct 27th, 2017. The long-running comment scraping script suffered from a pair of disconnections and I estimate that I misplaced ~50,000 feedback ensuing from of it. Regardless that the Uncover Neutrality Public Comment Length ended on August 30, 2017, the FCC ECFS machine persevered to utilize feedback afterwards, which had been integrated in the evaluation.
⁵ I mature an md5 hash feature, which had a low sufficient collision charge and allowed me to (barely) quick gather and count up duplicates. I tossed out submissions with no explicit comment text nevertheless otherwise did no longer enact any other text preprocessing on the text sooner than encoding and clustering in state to withhold artifacts in the text that might per chance simply give clues as to the manner of submission.
⁶ A large proportion of these ~three million “fascinating” feedback were if truth be told duplicates — completely differing by a pair of characters or phrases or having a utterly different signature. In state to conclusively and exhaustively categorize these feedback, I selected to neighborhood feedback by that manner. Comments were became into picture vectors created from the average of all phrase vectors in the comment. The phrase vectors were got from spaCy, which uses the phrase vectors from the paper by Levy and Goldberg (2014). [Correction from Matthew Honnibal: spaCy now uses the GloVe vectors by Pennington et al.]
⁷ I made two passes at clustering the picture vectors. First with DBSCAN with a euclidean distance metric at a extremely low epsilon to name evident clusters and cull them out manually using a string signature. This left ~2 million fascinating feedback. From that 2 million, I mature HDBSCAN on a a hundred,000 comment sample with cosine distance to name ‘looser’ clusters, and then mature approximate_predict()to classify remaining feedback as both within those identified clusters or as outliers. Eradicating duplicates, this resulted in decrease than 800,000 fascinating outlier “organic” feedback. [Correction: As HDBSCAN Creator Leland McInnes notes below, cosine distances don’t yet play effectively with HDBSCAN — to be proper, I mature the euclidean distance metric between l2-normalized doc vectors, which in overall works effectively as an alternate.]
⁸ Sized from the handfuls to the tens of millions.
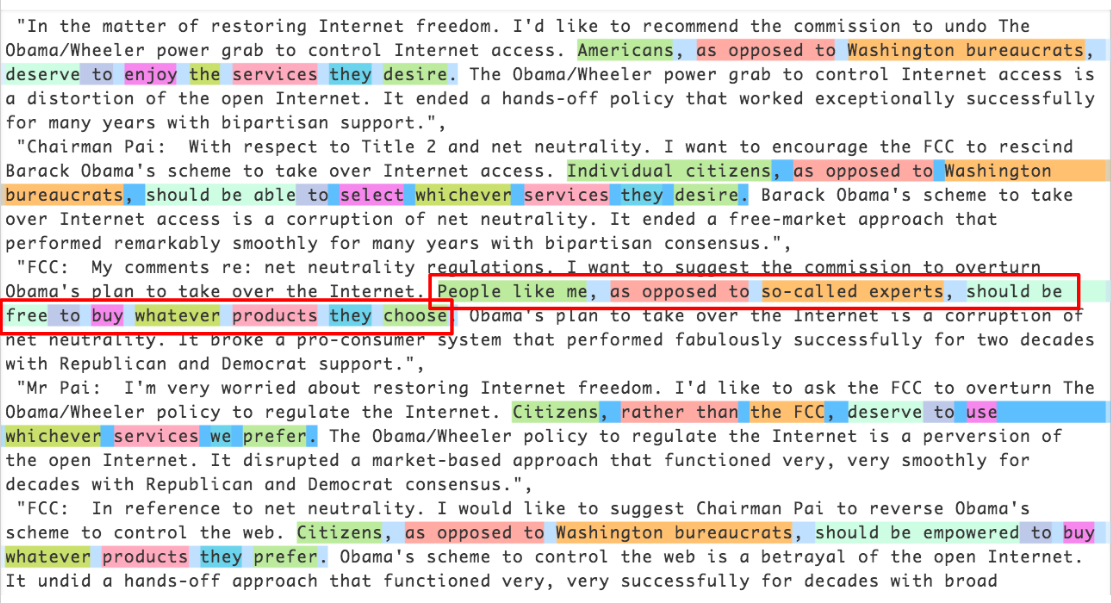
⁹ Strange Expression on this pastebin.
¹⁰ Here’s ensuing from the combinations of comment configurations grows exponentially with each and each space of synonyms introduced. Furthermore, to be proper, there were some infected-lib feedback that were duplicated once, nevertheless no longer extra than that.
¹¹ Page three of the Verizon Comments (submitted August 30, 2017)
¹² FCC Chairman Pai’s Observation re the Draft Convey (printed November 21, 2017)
¹³ Whereas there are surely other that that it is doubtless you’ll imagine explanations for this space of results, I mediate Occam’s Razor might per chance simply restful be conscious. Extra investigation into the timing and emails mature for this explicit campaign would supply extra corroborating proof.
¹⁴ Plotted on a log-scale so that that it is doubtless you’ll restful explore the colour of the smaller bars.
¹⁵ Because the author of the Gravwell survey states: “[The evidence] forces us to enact that both the very act of going to the FCC comment procedure and providing a comment is completely beautiful to those of a determined political leaning, or that the bulk submission info is stuffed with lies.”
¹⁶ Legitimate-repeal feedback are on traces 176, 228, 930 in the pastebin. There also looked as if it might most likely per chance per chance well be three accumulate neutrality supporters that gave the influence perplexed about the terminology (traces 332, 366, 901) and one script kiddie (line 261). It’s that that it is doubtless you’ll imagine I take into accout omitted one or two, and I’m gay to appropriate any errors on this comment space can take into accout to you look them.
¹⁷ My extra statistically-inclined colleague informs me that the central limit theorem breaks down on the unparalleled limits (the attach the inhabitants proportion is finish to zero% or a hundred% of a inhabitants), which I take into accout taken his phrase/expertise for, for now, and can simply restful be taught about later. [Edit: I take into accout stumbled on a gradual addition to this on a reddit comment. The interval is ninety 9.12% to ninety 9.90%, 19 times out of 20.]
¹⁸ Line 102 in the pastebin.
¹⁹ [A final late addition: Lest I am unintentionally giving the wrong impression to folks who haven’t been following the net neutrality debate as closely, I want to be clear that there were suspicious campaigns from all sides of the debate from the text-only analysis; however, none were as numerous and as intentionally disguised as the 1.3M ‘unique’ comments identified in the post.]
Learn Extra
Commentaires récents