
Introducing Cloud Textual drawl-to-Speech powered by DeepMind WaveNet know-how

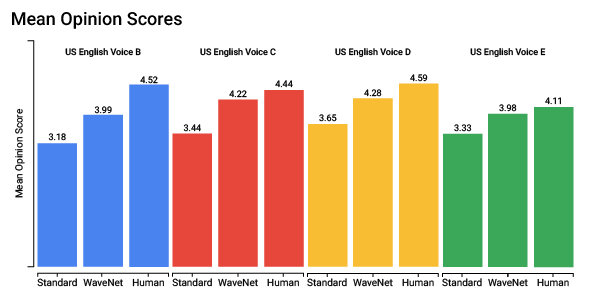
With these adjustments, the brand new WaveNet mannequin produces more pure sounding speech. In checks, people gave the brand new US English WaveNet voices an average mean-opinion-rating (MOS) of four.1 on a scale of 1-5 — over 20% better than for fashioned voices and reducing the gap with human speech by over 70%. As WaveNet voices also require much less recorded audio input to originate top effective fashions, we ask to continue to enhance each and every the vary as properly as effective of the WaveNet voices available within the market to Cloud potentialities within the approaching months.
Cloud Textual drawl-to-Speech is already serving to just a few potentialities negate a bigger trip to their destroy users. Prospects encompass Cisco and Dolphin ONE.
“As the main supplier of collaboration alternatives, Cisco has a lengthy history of bringing the most up-to-date know-how advances into the endeavor. Google’s Cloud Textual drawl-to-Speech has enabled us to operate the pure sound effective that our potentialities need. »
— Tim Tuttle, CTO of Cognitive Collaboration, Cisco
“Dolphin ONE’s Calll.io telephony platform provides connectivity from a multitude of devices, at virtually any spot. We’ve built-in Cloud Textual drawl-to-Speech into our merchandise and allow our users to manufacture pure name middle experiences. By utilizing Google Cloud’s machine discovering out tools, we’re straight away turning in slicing-edge know-how to our users.”
—Jason Berryman, Dolphin ONE
Bag started at the recent time
With Cloud Textual drawl-to-Speech, you’re now just a few clicks far from one amongst the most evolved speech applied sciences on this planet. To learn more, please discuss over with the
documentation or our
pricing page. To get started with our public beta or are trying out the brand new voices, discuss over with the Cloud Textual drawl-to-Speech
internet page.
Many Google merchandise (e.g., the Google Assistant, Search, Maps) attain with built-in high-effective textual drawl-to-speech synthesis that produces pure sounding speech. Developers were telling us they’d gain to add textual drawl-to-speech to their gain capabilities, so at the recent time we’re bringing this know-how to Google Cloud Platform with Cloud Textual drawl-to-Speech.
Potentialities are you’ll almost definitely well almost definitely also utilize Cloud Textual drawl-to-Speech in a vary of methods, let’s assert:
- To energy recount response programs for name services and products (IVRs) and enabling real-time pure language conversations
- To allow IoT devices (e.g., TVs, vehicles, robots) to discuss motivate to you
- To convert textual drawl-essentially based media (e.g., data articles, books) into spoken layout (e.g., podcast or audiobook)
Cloud Textual drawl-to-Speech lets you retract between 32 completely different voices from 12 languages and variants. Cloud Textual drawl-to-Speech precisely declares advanced textual drawl corresponding to names, dates, times and addresses for legitimate sounding speech real out of the gate. Cloud Textual drawl-to-Speech also lets you customize pitch, talking rate, and volume manufacture, and supports a vary of audio formats, in conjunction with MP3 and WAV.
Rolling within the DeepMind
In addition to, we’re angry to negate that Cloud Textual drawl-to-Speech also involves a replace of high-constancy voices built using WaveNet, a generative mannequin for raw audio created by DeepMind. WaveNet synthesizes more pure-sounding speech and, on average, produces speech audio that people gain over completely different textual drawl-to-speech applied sciences.
In slack 2016, DeepMind introduced the first model of WaveNet — a neural community educated with a beautiful volume of speech samples that’s ready to manufacture raw audio waveforms from scratch. All over coaching, the community extracts the underlying structure of the speech, let’s assert which tones be aware one one more and what form a sensible speech waveform will must gain. When given textual drawl input, the educated WaveNet mannequin generates the corresponding speech waveforms, one sample at a time, reaching better accuracy than replace approaches.
Rapidly forward to at the recent time, and we’re now using an updated model of WaveNet that runs on Google’s Cloud TPU infrastructure.The brand new, improved WaveNet mannequin generates raw waveforms 1,000 times sooner than the distinctive mannequin, and can generate one 2nd of speech in only 50 milliseconds. If truth be told, the mannequin is just not real quicker, but also better-constancy, helpful of developing waveforms with 24,000 samples a 2nd. We’ve also elevated the resolution of each and every sample from 8 bits to Sixteen bits, producing better effective audio for a more human sound.
With these adjustments, the brand new WaveNet mannequin produces more pure sounding speech. In checks, people gave the brand new US English WaveNet voices an average mean-opinion-rating (MOS) of four.1 on a scale of 1-5 — over 20% better than for fashioned voices and reducing the gap with human speech by over 70%. As WaveNet voices also require much less recorded audio input to originate top effective fashions, we ask to continue to enhance each and every the vary as properly as effective of the WaveNet voices available within the market to Cloud potentialities within the approaching months.
Cloud Textual drawl-to-Speech is already serving to just a few potentialities negate a bigger trip to their destroy users. Prospects encompass Cisco and Dolphin ONE.
“As the main supplier of collaboration alternatives, Cisco has a lengthy history of bringing the most up-to-date know-how advances into the endeavor. Google’s Cloud Textual drawl-to-Speech has enabled us to operate the pure sound effective that our potentialities need. »
— Tim Tuttle, CTO of Cognitive Collaboration, Cisco
“Dolphin ONE’s Calll.io telephony platform provides connectivity from a multitude of devices, at virtually any spot. We’ve built-in Cloud Textual drawl-to-Speech into our merchandise and allow our users to manufacture pure name middle experiences. By utilizing Google Cloud’s machine discovering out tools, we’re straight away turning in slicing-edge know-how to our users.”
—Jason Berryman, Dolphin ONE
Bag started at the recent time
With Cloud Textual drawl-to-Speech, you’re now just a few clicks far from one amongst the most evolved speech applied sciences on this planet. To learn more, please discuss over with the documentation or our pricing page. To get started with our public beta or are trying out the brand new voices, discuss over with the Cloud Textual drawl-to-Speech internet page.
Read Extra
Commentaires récents