
How I Shipped a Neural Network on iOS with CoreML, PyTorch, and React Native
That is the chronicle of how I trained a easy neural network to resolve a effectively-defined yet original remark in a proper iOS app. The remark is piquant, nonetheless most of what I cowl must tranquil apply to any job in any iOS app. That’s the elegance of neural networks.
I’ll stroll you by strategy of every step, from remark the full formulation to App Retailer. On the formulation we’ll take a transient detour into an different plan the usage of easy math (fail), by strategy of instrument constructing, dataset generation, neural network architecting, and PyTorch coaching. We’ll suffer the treacherous CoreML model converting to at closing reach the React Native UI.
If this feels esteem too prolonged a drag, to now not worry. You may per chance per chance click the left facet of this page to skip around. And if you happen to’re staunch shopping for a tl;dr, listed below are some links:
code, test UI, iOS app, and my Twitter.
The Squawk
I currently constructed a piece of iOS app for mechanical gaze fanciers to trace the accuracy of their watches over time.

In the app, gaze owners add measurements by tapping the conceal when their gaze reveals a determined time. Over time these measurements uncover the chronicle of how every gaze is performing.
Mechanical Note Rabbit Gap
Whenever you happen to don’t delight in a mechanical gaze, it’s seemingly you’ll well per chance also be pondering: what’s the level? The level of the app? No, the level of mechanical watches! My $forty Swatch is completely correct. So is my iPhone, for that matter. I discover, you’re one among those. Undergo with me. Proper know that mechanical watches be triumphant in or lose about a seconds daily – if they’re upright. Dreadful ones stray by about a minutes. Factual or defective, they discontinue working if you happen to don’t wind them. Both formulation or now not you’ll need to reset them veritably. And or now not you’ll need to carrier them. If they arrive wherever shut to a magnet, they open working wild except an skilled waves a piquant machine around them whereas muttering about a incantations.
Honest gaze enthusiasts obsess about caring for their watches, and measuring their accuracy is an importart segment of the ritual. How else would yours is the ideally good? Or if it wants carrier? It also helps within the rare case it’s seemingly you’ll well per chance also want to – – uncover what time it’s.
The famous characteristic of the app is a piece of chart, with functions plotting how your gaze has deviated from latest time, and trendlines estimating how your gaze is doing.

Computing a trendline given some functions is easy. Utilize a linear regression.
Nonetheless, mechanical watches must tranquil be reset to the latest time veritably. Perchance they waft too removed from latest time, or even you neglect a gaze for a day or two, it runs out of juice, and stops. These events manufacture a “ruin” within the trendline. As an illustration:

I didn’t wear that gaze for a few days. After I picked it up once more, I had to initiate over from zero.
I needed the app to reward separate trendlines for every of those runs, nonetheless I didn’t want my customers to want to end extra work. I would robotically determine the set apart to ruin up the trendlines. How tough may per chance well it be?

My thought became to Google my formulation out the problem, as one does. I quickly chanced on the edifying keywords: segmented regression, and piecewise linear regression. Then I chanced on one person that solved this proper remark the usage of long-established math. Jackpot!
Or now not. That plan tries to ruin up the trendline at every that it’s seemingly you’ll well per chance believe level after which decides which splits to pick out per how great they strengthen the mean squared error. Fee a shot, I guess.
Turns out this solution is amazingly dazzling to the parameters you bewitch, esteem how great decrease the error needs to be for a ruin as much as be regarded as price conserving. So I constructed a UI to support me tweak the parameters. You may per chance per chance discover what it seems esteem here.

No matter how I tweaked the parameters, the algorithm became both splitting too continually, or now not continually ample. This vogue wasn’t going to minimize it.
I’ve experimented for years with neural networks, nonetheless by no technique yet had had the different to make spend of 1 in a shipping app. This became my probability!
The Instruments
I reached for my neural networking tools. My thoughts became position that this may per chance occasionally now not staunch be every other experiment, so I had one request to answer to first: how would I deploy my trained model? Many tutorials log out on the end of coaching and whisk away this segment out.
This being an iOS app, the evident answer became CoreML. It’s the ideally good formulation I do know of to whisk predictions on the GPU; closing I checked CUDA became now not obtainable on iOS.
Another abet of CoreML is that it’s constructed in to the OS, so I wouldn’t want to stress about compiling, linking, and shipping binaries of ML libraries with my runt app.
CoreML Caveats
CoreML is extremely unique. It ideally good helps a subset of all that it’s seemingly you’ll well per chance believe layers and operations. The tools that Apple ships ideally good convert devices trained with Keras. Ironically, Keras devices don’t appear to operate effectively on CoreML. Whenever you happen to profile a transformed Keras model you’ll witness a estimable deal of time spent shuffling data into Caffe operations and help. It appears seemingly that Apple uses Caffe internally, and Keras strengthen became tacked on. Caffe does now not strike me as a estimable compile goal for a Keras/TensorFlow model. In particular if you happen to’re now not facing footage.
I’d had mixed luck converting Keras devices to CoreML, which is the Apple-sanctioned path (discover field above), so became on the hunt for other ways to generate CoreML devices. Meanwhile, I became shopping for an excuse to take a peep at out PyTorch (discover field under). Somewhere alongside the formulation I stumbled upon ONNX, a proposed commonplace alternate layout for neural network devices. PyTorch is supported from day one. It occurred to me to peep for an ONNX to CoreML converter, and obvious ample, one exists!
What about Keras and TensorFlow?
Devour most folk, I minimize my neural enamel on TensorFlow. But my honeymoon length had ended. I became getting weary of the kitchen-sink technique to library administration, the immense binaries, and the extremely dull startup instances when coaching. TensorFlow APIs are a sprawling mess. Keras mitigates that remark rather, nonetheless it’s a leaky abstraction. Debugging is hard if you happen to don’t realize how issues work under.
PyTorch is a breath of original air. It’s faster to initiate up, which makes iterating more rapid and fun. It has a smaller API, and a more perfect execution model. Now not like TensorFlow, it does now not construct you originate a computation graph in come, with none perception or adjust of the plan in which it gets completed. It feels a long way more esteem long-established programming, it makes issues more uncomplicated to debug, and likewise permits more dynamic architectures – which I haven’t used yet, nonetheless a boy can dream.
I at closing had the full devices of the puzzle. I knew how I would educate the network and I knew how I would deploy it on iOS. Nonetheless, I knew from some of my earlier experiments that many issues may per chance well tranquil whisk unfavorable. Merely one formulation to gain out.
Gathering the Working in direction of Data
In my expertise with neural networks, assembling a estimable-ample quality dataset to coach on is the toughest segment. I believe here is why most papers and tutorials initiate with a illustrious public dataset, esteem MNIST.
Nonetheless, I esteem neural networks precisely because they may per chance per chance be applied to unique and attention-grabbing problems. So I craft brew my delight in micro-datasets. Since my datasets are small, I restrict myself to problems which may per chance well be a piece of more manageable than your whisk-of-the-mill Van Gogh-vogue portrait generation venture.
Fortunately, the problem at hand is easy (or so I view), so a small dataset must tranquil end. On high of that, it’s a visible remark, so producing data and evaluating the neural networks must tranquil be easy… given a mouse, a pair of eyes, and the edifying instrument.
The Take a look at UI
I had the ideally good UI already. I’d constructed it to tweak the parameters of my easy-math algorithm and discover the ends up in proper time. It didn’t take me prolonged to convert it correct into a UI for producing coaching examples. I added the choice to specify the set apart I view runs must tranquil ruin up.

With about a clicks and a JSON.stringify call, I had ample data to soar into Python.
Parcel
As an skilled net developer, I knew constructing this UI as an online app with React became going to be easy. Nonetheless, there became one segment I became dreading, although I’ve performed it dozens of instances sooner than: configuring Webpack. So I took this as a possibility to take a peep at Parcel. Parcel labored out-of-the-field with zero configuration. It even labored with TypeScript. And sizzling code reload. I became in a position to have an completely working net app faster than typing
manufacture-react-app.
Preprocessing the Data
Another long-established hurdle when designing a neural network is finding the optimal formulation to encode something fuzzy, esteem textual swear material of tons of lengths, into numbers a neural networks can realize. Fortunately, the problem at hand is numbers to initiate with.
In my dataset, every instance is a group of [x, y] coordinates, one for every of the functions within the input. I actually have a list of coordinates for every of the splits that I’ve manually entered – which is what I will seemingly be coaching the network to be taught.
The above, as JSON, seems esteem this:
{
"functions": [
[forty three, 33], [86, 69], [152, ninety four], [a hundred seventy five, 118], [221, 156],
[247, 38], [279, sixty one], [303, 89],
[329, 34], [369, fifty six], [392, seventy six], [422, 119], [461, 128],
[470, 34], [500, Fifty seven], [525, Ninety three], [542, 114], [582, 138]],
"splits": [
235,
320,
467,
]
}
All I had to end to feed the list of functions correct into a neural network became to pad it to a fixed size. I picked a amount that felt estimable ample for my app (100). So I fed the network a 100-prolonged collection of pairs of floats (a.k.a. a tensor of shape [100, 2]).
[[forty three, 33], [86, 69], [152, ninety four], [a hundred seventy five, 118], [221, 156], [247, 38], [279, sixty one], [303, 89], ... [0, 0], [0, 0], [0, 0]]
The output is a group of bits, with ones marking a group apart the set apart the trendline must tranquil be ruin up. That is also within the form [100] – i.e. array of size 100.
[0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, ... 0, 0, 0]
There are ideally good Ninety nine that it’s seemingly you’ll well per chance believe splits, since it doesn’t construct sense to ruin up at set apart 100. Nonetheless, conserving the scale the same simplifies the neural network. I’ll ignore the closing bit within the output.
Because the neural network tries to approximate this collection of ones and zeros, every output amount will drop someplace in-between. We’re going to be in a position to clarify those because the probability that a ruin up must tranquil happen at a determined level, and ruin up wherever above a determined self belief designate (veritably 0.5).
[0, 0.0002, 0, 0, 1, 0, 0, 0.1057, 0, 0.0020, 0, 0.3305, 0.9997, 0, 0, 0, 0, 0, ... 0, 0, 0]
In this case, it’s seemingly you’ll well per chance discover that the network is elegant confident we must tranquil ruin up at positions 5 and 13 (correct!), nonetheless it’s now not so obvious about set apart eight (unfavorable). It also thinks 12 may per chance be a candidate, nonetheless now not confident ample to call it (correct).
Encoding the Inputs
I esteem to factor out the info encoding logic into its delight in characteristic, as I veritably want it in more than one areas (coaching, review, and on occasion even manufacturing).
My encode characteristic takes a single instance (a group of functions of variable size), and returns a fixed-size tensor. I started with something that returned an empty tensor of the edifying shape:
import torch
def encode(functions, padded_length=100):
input_tensor = torch.zeros([2, padded_length])
return input_tensor
Display that it’s seemingly you’ll well per chance already spend this to initiate coaching and working your neural network, sooner than you assign in any proper data. It received’t be taught something ample, nonetheless as a minimum you’ll know your architecture works sooner than you invest more time into making ready your data.
Next I possess within the tensor with data:
import torch
def encode(functions, padded_length=100):
input_tensor = torch.zeros([2, padded_length])
for i in differ(min(padded_length, len(functions))):
input_tensor[0][i] = functions[i][0] * 1.0
input_tensor[1][i] = functions[i][1] * 1.0
continue
return input_tensor
Advise of Coordinates in PyTorch vs TensorFlow
Whenever you happen to’re paying consideration, you are going to need seen that the x/y coordinate comes sooner than the set apart. In other words, the form of every instance is
[2, 100], now not[100, 2]as you will assign a matter to – especially if you happen to’re coming from TensorFlow. PyTorch convolutions (discover later) assign a matter to coordinates in a determined show: the channel (x/y on this case, r/g/b in case of a image) comes sooner than the index of the level.
Normalization
I now have the info in a layout the neural network can gain. I could per chance well discontinue here, nonetheless it’s upright be conscious to normalize the inputs so as that the values cluster around 0. That is the set apart floating level numbers have the very ideally good precision.
I gain the minimum and most coordinates in every instance and scale the full lot proportionally.
import torch
def encode(functions, padded_length=100):
xs = [p[0] for p in functions]
ys = [p[1] for p in functions]
min_x = min(xs)
max_x = max(xs)
min_y = min(ys)
max_y = max(ys)
y_shift = ((max_y - min_y) / (max_x - min_x)) / 2.0
input_tensor = torch.zeros([2, padded_length])
def normalize_x(x):
return (x - min_x) / (max_x - min_x) - 0.5
def normalize_y(y):
return (y - min_y) / (max_x - min_x) - y_shift
for i in differ(min(padded_length, len(functions))):
input_tensor[0][i] = normalize_x(functions[i][0] * 1.0)
input_tensor[1][i] = normalize_y(functions[i][1] * 1.0)
continue
return input_tensor
Processing Inner the Network
Most of the operations I’m writing in Python, esteem normalization, casting, etc., will be found as operations interior most machine studying libraries. You may per chance per chance well implement them that formulation, and so they may per chance per chance well be more efficient, potentially even working on the GPU. Nonetheless, I chanced on that these kinds of operations aren’t supported by CoreML.
What about Characteristic Engineering?
Characteristic engineering is the strategy of additional massaging the input in show to present the neural network a head-initiate. As an illustration, on this case I could per chance well feed it now not ideally good the
[x, y]of every level, nonetheless also the distance, horizontal and vertical gaps, and slope of the road between every pair. Nonetheless, I preserve to own that my neural network can be taught to compute whatever it wants out of the input. In level of fact, I did strive feeding a bunch of derived values as input, nonetheless that did now not appear to support.
The Model
Now comes the fun segment, in actuality defining the neural network architecture. Since I’m facing spatial data, I reached for my accepted more or less neural network layer: the convolution.
Convolution
I own convolution as code reuse for neural networks. An extended-established completely-associated layer has no belief of set and time. By the usage of convolutions, you’re telling the neural network it will reuse what it realized across determined dimensions. In my case, it doesn’t matter the set apart within the sequence a determined sample occurs, the logic is a associated, so I spend a convolution across the time dimension.
Convolutions as Performance Optimizations
A compulsory realization is that, though convolutions sound… convoluted, their famous abet is that they in actuality simplify the network. By reusing logic, networks compile smaller. Smaller networks want less data and are faster to coach.
What about RNNs?
Recurrent neural networks (RNNs) are widespread when facing sequential data. Roughly talking, as an different of getting a peep on the full input straight away, they project the sequence in show, originate up a “memory” of what came about sooner than, and spend that memory to deem what occurs next. This makes them a estimable fit for any sequence. Nonetheless, RNNs are more complex, and as such take more time – and more data – to coach. For smaller problems esteem this, RNNs are inclined to be overkill. Plus, fresh papers have shown that effectively designed CNNs may per chance well make same outcomes faster than RNNs, even at tasks on which RNNs historically shine.
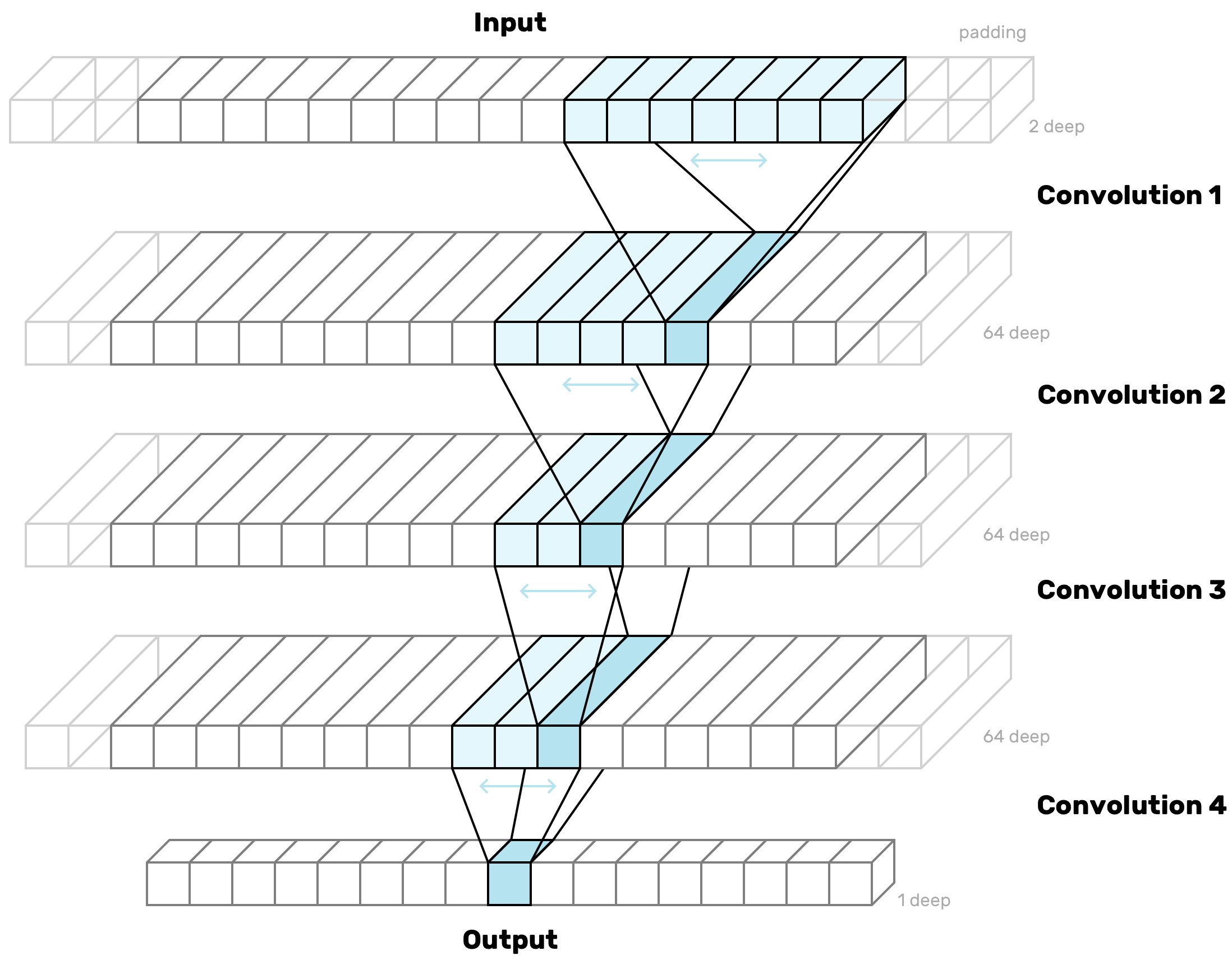
Structure
Convolutions are very spatial, that technique or now not you’ll need to have an unheard of intuitive view of the form of the info they assign a matter to as input and the form of their output. I are inclined to sketch or visualize diagrams esteem these when I make my convolutional layers:

The diagram reveals the shapes of the functions (a.k.a. kernels) that convert every layer into the subsequent by sliding over the input from beginning to end, one slot at a time.
I’m stacking convolutional layers esteem this for two causes. First, stacking layers in long-established has been shown to support networks be taught gradually more abstract concepts – here is why deep studying is so widespread. 2d, because it’s seemingly you’ll well per chance discover from the diagram above, with every stack the kernels fan out, esteem an upside-down tree. Every piece within the output layer gets to “discover” an increasing vogue of of the input sequence. That is my formulation of giving every level within the output more info about its context.
The goal is to tweak the tons of parameters so the network gradually transforms the form of the input into the form of my output. Meanwhile I adjust the 1/three dimension (depth) so as that there’s ample “room” to lift forward staunch the edifying amount of data from the old layers. I don’t want my layers to be too small, otherwise there may per chance be too great data misplaced from the old layers, and my network will fight to construct sense of something. I don’t want them to be too giant both, because they’ll take longer to coach, and, quite seemingly, they’ll have ample “memory” to be taught every of my examples for my part, as an different of being compelled to fabricate a abstract that will be higher at generalizing to by no technique-sooner than-viewed examples.
No Entirely-Linked Layers?
Most neural networks, even convolutional ones, spend one or more “completely-associated” (a.k.a. “dense”) layers, i.e. the ideally good more or less layer, the set apart every neuron within the layer is hooked as much as every neuron within the old layer. The object about dense layers is that they originate now not have any sense of set (which capacity fact the title “dense”). Any spatial data is misplaced. This makes them estimable for long-established classification tasks, the set apart your output is a group of labels for the full input. In my case, the output is as sequential because the input. For every level within the input there’s a probability designate within the output representing whether or to now not ruin up there. So I want to pick out the spatial data the full formulation by strategy of. No dense layers here.
PyTorch Model
To install PyTorch, I followed the instructions on the PyTorch homepage:
pip install http://bag.pytorch.org/whl/torch-0.three.0.post4-cp27-none-macosx_10_6_x86_64.whl
That is how the above structure translates to PyTorch code. I subclass nn.Module, and within the constructor I clarify every layer I want. I’m selecting padding values carefully to pick out the scale of my input. So if I even have a convolution kernel that’s 7 huge, I pad by three on all sides so as that the kernel tranquil has room to heart on the first and closing positions.
import torch.nn as nn
input_channels = 2
intermediate_channels = Sixty four
output_channels = 1
class Model(nn.Module):
def __init__(self):
natty(Model, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv1d(in_channels=input_channels, out_channels=channels, kernel_size=7, padding=three),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=channels, kernel_size=5, padding=2),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=channels, kernel_size=three, padding=1),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=output_channels, kernel_size=three, padding=1),
nn.Sigmoid(),
)
The total layers spend the widespread ReLU activation characteristic, moreover the closing one which uses a sigmoid. That’s so the output values compile squashed into the 0–1 differ, so they drop someplace between the ones and zeros I’m providing as goal values. Very without problems, numbers on this differ may per chance be interpreted as probabilities, which is why the sigmoid activation characteristic is widespread within the closing layer of neural networks designed for classification tasks.
The following step is to clarify a forward() plan, which is in a position to in actuality be known as on every batch of your data all over coaching:
import torch.nn as nn
input_channels = 2
intermediate_channels = Sixty four
output_channels = 1
class Model(nn.Module):
def __init__(self):
natty(Model, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv1d(in_channels=input_channels, out_channels=channels, kernel_size=7, padding=three),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=channels, kernel_size=5, padding=2),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=channels, kernel_size=three, padding=1),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
nn.Conv1d(in_channels=intermediate_channels, out_channels=output_channels, kernel_size=three, padding=1),
nn.Sigmoid(),
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.discover(-1, x.size(three))
return x
The forward plan feeds the info by strategy of the convolutional layers, then flattens the output and returns it.
This vogue is what makes PyTorch in actuality feel in actuality tons of than TensorFlow. You’re writing proper Python code that can in actuality be completed all over coaching. If errors happen, they’re going to happen on this characteristic, which is code you wrote. You may per chance per chance add print statements to head attempting for the info you’re getting and determine what’s occurring.
Working in direction of
To coach a network in PyTorch, you manufacture a dataset, wrap it in an data loader, then loop over it except your network has realized ample.
PyTorch Dataset
To manufacture a dataset, I subclass Dataset and clarify a constructor, a __len__ plan, and a __getitem__ plan. The constructor is the ideally good plot to read in my JSON file with the full examples:
import json
import torch
from torch.utils.data import Dataset
class PointsDataset(Dataset):
def __init__(self):
self.examples = json.load(originate('data.json'))
I return the scale in __len__:
import json
import torch
from torch.utils.data import Dataset
class PointsDataset(Dataset):
def __init__(self):
self.examples = json.load(originate('data.json'))
def __len__(self):
return len(self.examples)
In the end, I return the input and output data for a single instance from __getitem__. I spend encode() defined earlier to encode the input. To encode the output, I manufacture a unique tensor of the edifying shape, possess it with zeros, and insert a 1 at every set apart the set apart there must tranquil be a ruin up.
import json
import torch
from torch.utils.data import Dataset
class PointsDataset(Dataset):
def __init__(self):
self.examples = json.load(originate('data.json'))
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
instance = self.examples[idx]
input_tensor = encode(instance['functions'])
output_tensor = torch.zeros(100)
for split_position in instance['splits']:
index = next(i for i, level in
enumerate(instance['functions']) if level[0] > split_position)
output_tensor[index - 1] = 1
return input_tensor, output_tensor
I then instantiate the dataset:
dataset = PointsDataset()
Atmosphere Apart a Validation Build
I want to position apart one of the most vital data to pick out song of how my studying goes. This known as a validation position. I esteem to robotically ruin up out a random subset of examples for this goal. PyTorch doesn’t provide an effortless formulation to end that out of the sphere, so I used PyTorchNet. It’s now not in PyPI, so I assign in it straight from GitHub:
pip install git+https://github.com/pytorch/tnt.git
I drag the dataset correct sooner than splitting it, so as that the ruin up is random. I take out 10% of my examples for the validation dataset.
from torchnet.dataset import SplitDataset, ShuffleDataset
dataset = PointsDataset()
dataset = SplitDataset(ShuffleDataset(dataset), {'educate': 0.9, 'validation': 0.1})
SplitDataset will let me swap between the two datasets as I alternate between coaching and validation later.
Take a look at Build
It’s mature to position apart a 1/three position of examples, known as the test position, which you by no technique contact as you’re growing the network. The test position is used to substantiate that your accuracy on the validation position became now not a fluke. For now, with a dataset this small, I don’t have the sumptuous of conserving more data out of the coaching position. As for sanity checking my accuracy… working in manufacturing with proper data will want to end!
PyTorch DataLoader
One more hoop to soar by strategy of. Data loaders spit out data from a dataset in batches. That is what you without a doubt feed the neural network all over coaching. I manufacture an data loader for my dataset, configured to fabricate batches which may per chance well be small and randomized.
from torchnet.dataset import SplitDataset, ShuffleDataset
dataset = PointsDataset(data_file)
dataset = SplitDataset(ShuffleDataset(dataset), {'educate': 0.9, 'validation': 0.1})
loader = DataLoader(dataset, drag=Honest, batch_size=6)
The Working in direction of Loop
Time to initiate coaching! First I uncover the model it’s time to coach:
Then I initiate my loop. Every iteration known as an epoch. I started with a small selection of epochs after which experimented to gain the optimal amount later.
model.educate()
for epoch in differ(a thousand):
Take our coaching dataset:
model.educate()
for epoch in differ(a thousand):
dataset.bewitch out('educate')
Then I iterate over the full dataset in batches. The data loader will very very without problems give me inputs and outputs for every batch. All I want to end is wrap them in a PyTorch Variable.
from torch.autograd import Variable
model.educate()
for epoch in differ(a thousand):
dataset.bewitch out('educate')
for i, (inputs, goal) in enumerate(loader):
inputs = Variable(inputs)
goal = Variable(goal)
Now I feed the model! The model spits out what it thinks the output must tranquil be.
model.educate()
for epoch in differ(a thousand):
dataset.bewitch out('educate')
for i, (inputs, goal) in enumerate(loader):
inputs = Variable(inputs)
goal = Variable(goal)
logits = model(inputs)
After that I end some esteem math to establish how a long way off the model is. Most of the complexity is so as that I will ignore (“veil”) the output for functions which may per chance well be staunch padding. The attention-grabbing segment is the F.mse_loss() call, which is the mean squared error between the guessed output and what the output must tranquil in actuality be.
model.educate()
for epoch in differ(a thousand):
dataset.bewitch out('educate')
for i, (inputs, goal) in enumerate(loader):
inputs = Variable(inputs)
goal = Variable(goal)
logits = model(inputs)
veil = inputs.eq(0).sum(dusky=1).eq(0)
float_mask = veil.waft()
masked_logits = logits.mul(float_mask)
masked_target = goal.mul(float_mask)
loss = F.mse_loss(logits, goal)
In the end, I backpropagate, i.e. take that error and spend it to tweak the model to be more correct next time. I want an optimizer to end this work for me:
model.educate()
optimizer = torch.optim.Adam(model.parameters())
for epoch in differ(a thousand):
dataset.bewitch out('educate')
for i, (inputs, goal) in enumerate(loader):
inputs = Variable(inputs)
goal = Variable(goal)
logits = model(inputs)
veil = inputs.eq(0).sum(dusky=1).eq(0)
float_mask = veil.waft()
masked_logits = logits.mul(float_mask)
masked_target = goal.mul(float_mask)
loss = F.mse_loss(logits, goal)
optimizer.zero_grad()
loss.backward()
optimizer.step()
As soon as I’ve long passed by strategy of the full batches, the epoch is over. I spend the validation dataset to calculate and print out how the studying goes. Then I initiate over with the subsequent epoch. The code within the review() characteristic must tranquil peep familiar. It does the same work I did all over coaching, moreover the usage of the validation data and with some extra metrics.
model.educate()
optimizer = torch.optim.Adam(model.parameters())
for epoch in differ(a thousand):
dataset.bewitch out('educate')
for i, (inputs, goal) in enumerate(loader):
inputs = Variable(inputs)
goal = Variable(goal)
logits = model(inputs)
veil = inputs.eq(0).sum(dusky=1).eq(0)
float_mask = veil.waft()
masked_logits = logits.mul(float_mask)
masked_target = goal.mul(float_mask)
loss = F.mse_loss(logits, goal)
optimizer.zero_grad()
loss.backward()
optimizer.step()
dataset.bewitch out('validation')
validation_loss, validation_accuracy, correct, complete = review(model, next(iter(loader)))
print 'r[{:4d}] - validation loss: {:eight.6f} - validation accuracy: {:6.3f}% ({}/{} correct)'.layout(
epoch + 1,
validation_loss,
validation_accuracy,
correct,
complete
),
sys.stdout.flush()
def review(model, data):
inputs, goal = data
inputs = Variable(inputs)
goal = Variable(goal)
veil = inputs.eq(0).sum(dusky=1).eq(0)
logits = model(inputs)
correct = int(logits.round().eq(goal).mul(veil).sum().data)
complete = int(veil.sum())
accuracy = 100.0 * correct / complete
float_mask = veil.waft()
masked_logits = logits.mul(float_mask)
masked_target = goal.mul(float_mask)
loss = F.mse_loss(logits, goal)
return waft(loss), accuracy, correct, complete
Time to whisk it. That is what the output seems esteem.
[ 1] validation loss: 0.084769 - validation accuracy: 86.667% (fifty two/60 correct)
[ 2] validation loss: 0.017048 - validation accuracy: 86.667% (fifty two/60 correct)
[ three] validation loss: 0.016706 - validation accuracy: 86.667% (fifty two/60 correct)
[ four] validation loss: 0.016682 - validation accuracy: 86.667% (fifty two/60 correct)
[ 5] validation loss: 0.016677 - validation accuracy: 86.667% (fifty two/60 correct)
[ 6] validation loss: 0.016675 - validation accuracy: 86.667% (fifty two/60 correct)
[ 7] validation loss: 0.016674 - validation accuracy: 86.667% (fifty two/60 correct)
[ eight] validation loss: 0.016674 - validation accuracy: 86.667% (fifty two/60 correct)
[ 9] validation loss: 0.016674 - validation accuracy: 86.667% (fifty two/60 correct)
[ 10] validation loss: 0.016673 - validation accuracy: 86.667% (fifty two/60 correct)
...
[ 990] validation loss: 0.008275 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 991] validation loss: 0.008275 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 992] validation loss: 0.008286 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 993] validation loss: 0.008291 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 994] validation loss: 0.008282 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 995] validation loss: 0.008292 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 996] validation loss: 0.008293 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 997] validation loss: 0.008297 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 998] validation loss: 0.008345 - validation accuracy: Ninety two.308% (48/fifty two correct)
[ 999] validation loss: 0.008338 - validation accuracy: Ninety two.308% (48/fifty two correct)
[a thousand] validation loss: 0.008318 - validation accuracy: Ninety two.308% (48/fifty two correct)
Because it’s seemingly you’ll well per chance discover the network learns elegant swiftly. In this particular whisk, the accuracy on the validation position became already at 87% on the end of the first epoch, peaked at ninety four% around epoch 220, then settled at around Ninety two%. (I potentially will have stopped it sooner.)
Plan Cases
This network is small ample to coach in about a minutes on my depressed pale first-generation Macbook Adorable. For coaching larger networks, nothing beats the price/performance ratio of an AWS GPU-optimized set occasion. Whenever you happen to end tons of machine studying and may per chance’t give you the cash for a Tesla, you owe it to yourself to jot down a piece of script to hump up an occasion and whisk coaching on it. There are estimable AMIs obtainable that consist of the full lot required, at the side of CUDA.
Evaluating
My accuracy outcomes were elegant respectable out of the gate. To in actuality realize how the network became performing, I fed the output of the network help into the test UI, so I could per chance well visualize the plan in which it succeeded and the plan in which it failed.
There were many refined examples the set apart it became set on, and it made me a proud daddy:
Because the network bought higher, I started pondering up an increasing vogue of inappropriate examples. Devour this pair:
I quickly realized that the problem became formulation more sturdy than I had imagined. Composed, the network did effectively. It bought to the level the set apart I would cook dinner up examples I became now not be determined easy solutions to ruin up myself. I would belief the network to figure it out. Devour with this loopy one:
Even when it “fails”, in step with my arbitrary inputs, it’s arguably staunch as correct as I am. As soon as in a while it even makes me request my delight in judgment. Devour, what became I pondering here?
No, it’s now not pleasurable. Right here’s an instance the set apart it clearly fails. I forgive it though: I would have made that mistake myself.
I’m quite contented with these outcomes. I’m cheating a piece of bit here, since these kinds of examples I’ve already used to coach the network. Operating within the app on proper data may per chance well be the right kind test. Composed, this seems a long way more promising than the easy plan I used earlier. Time to ship it!
Deploying
Adapting to ONNX/CoreML
I’m now not gonna lie, this became the scariest segment. The conversion to CoreML is a minefield lined in roadblocks and littered with pitfalls. I came shut to giving up here.
My first fight became getting the full forms correct. On my first few tries I fed the network integers (such is my input data), nonetheless some form cast became inflicting the CoreML conversion to fail. In this case I labored around it by explicitly casting my inputs to floats all over preprocessing. With other networks – especially ones that spend embeddings – I haven’t been so lucky.
Another topic I ran into is that ONNX-CoreML does now not strengthen 1D convolutions, the form I spend. No matter being more perfect, 1D convolutions are always the underdog, because working with textual swear material and sequences is now not as chilly as working with footage. Fortunately, it’s elegant easy to reshape my data in an effort to add an additional bogus dimension. I changed the model to make spend of 2D convolutions, and I used the discover() plan on the input tensor to reshape the info to check what the 2D convolutions assign a matter to.
import torch.nn as nn
input_channels = 2
intermediate_channels = Sixty four
class Model(nn.Module):
def __init__(self):
natty(Model, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=input_channels, out_channels=channels, kernel_size=(1, 7), padding=(0, three)),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=intermediate_channels, out_channels=channels, kernel_size=(1, 5), padding=(0, 2)),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=intermediate_channels, out_channels=channels, kernel_size=(1, three), padding=(0, 1)),
nn.ReLU(),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=intermediate_channels, out_channels=1, kernel_size=(1, three), padding=(0, 1)),
nn.Sigmoid(),
)
def forward(self, x):
x = x.discover(-1, x.size(1), 1, x.size(2))
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = x.discover(-1, x.size(three))
return x
ONNX
As soon as those tweaks were performed, I became at closing in a position to export the trained model as CoreML, by strategy of ONNX. To export as ONNX, I known as the export characteristic with an instance of what the input would peep esteem.
import torch
from torch.autograd import Variable
dummy_input = Variable(torch.FloatTensor(1, 2, 100))
torch.onnx.export(model, dummy_input, 'SplitModel.proto', verbose=Honest)
ONNX-CoreML
To convert the ONNX model to CoreML, I used ONNX-CoreML.
The model of ONNX-CoreML on PyPI is broken, so I assign within the latest model straight from GitHub:
pip install git+https://github.com/onnx/onnx-coreml.git
Makefile
I indulge in writing Makefiles. They’re esteem READMEs, nonetheless more uncomplicated to whisk. I want about a dependencies for this venture, many of which have irregular install procedures. I also esteem to make spend of
virtualenvto install Python libraries, nonetheless I don’t want to want to assign in thoughts to set off it. This Makefile does the full above for me. I staunch whiskconstruct educate.VIRTUALENV:=$(shell which virtualenv) ENV=env SITE_PACKAGES=$(ENV)/lib/python2.7/set-packages PYTHON=/usr/bin/python LOAD_ENV=offer $(ENV)/bin/set off env: $(VIRTUALENV) virtualenv env --python=$(PYTHON) $(SITE_PACKAGES)/torch: $(LOAD_ENV) && pip install http://bag.pytorch.org/whl/torch-0.three.0.post4-cp27-none-macosx_10_6_x86_64.whl $(SITE_PACKAGES)/onnx_coreml: $(LOAD_ENV) && pip install git+https://github.com/onnx/onnx-coreml.git $(SITE_PACKAGES)/torchnet: $(LOAD_ENV) && pip install git+https://github.com/pytorch/tnt.git SplitModel.mlmodel: env $(SITE_PACKAGES)/torch $(SITE_PACKAGES)/onnx_coreml $(SITE_PACKAGES)/torchnet educate.py data.json $(LOAD_ENV) && python educate.py educate: @contact data.json @construct SplitModel.mlmodel .PHONY: educate
I load the ONNX model help in:
import torch
from torch.autograd import Variable
import onnx
dummy_input = Variable(torch.FloatTensor(1, 2, 100))
torch.onnx.export(model, dummy_input, 'SplitModel.proto', verbose=Honest)
model = onnx.load('SplitModel.proto')
And convert it to a CoreML model:
import torch
from torch.autograd import Variable
import onnx
from onnx_coreml import convert
dummy_input = Variable(torch.FloatTensor(1, 2, 100))
torch.onnx.export(model, dummy_input, 'SplitModel.proto', verbose=Honest)
model = onnx.load('SplitModel.proto')
coreml_model = convert(
model,
'classifier',
image_input_names=['input'],
image_output_names=['output'],
class_labels=[i for i in differ(100)],
)
In the end, I build the CoreML model to a file:
import torch
from torch.autograd import Variable
import onnx
from onnx_coreml import convert
dummy_input = Variable(torch.FloatTensor(1, 2, 100))
torch.onnx.export(model, dummy_input, 'SplitModel.proto', verbose=Honest)
model = onnx.load('SplitModel.proto')
coreml_model = convert(
model,
'classifier',
image_input_names=['input'],
image_output_names=['output'],
class_labels=[i for i in differ(100)],
)
coreml_model.build('SplitModel.mlmodel')
CoreML
As soon as I had a trained CoreML model, I became in a position to dawdle the model into Xcode:

Next step became to whisk it, so here comes the Swift code! First, I be determined I’m working on iOS eleven or bigger.
import CoreML
func ruin up(functions: [[Float32]]) -> [Int]? {
if #obtainable(iOS eleven.0, *) {
} else {
return nil
}
}
Then I manufacture a MLMultiArray and possess it with the input data. To end so I had to port over the encode() logic from earlier. The Swift API for CoreML is clearly designed for Plot-C, which capacity fact the full awkward form conversions. Fix it, Apple, kthx.
import CoreML
func ruin up(functions: [[Float32]]) -> [Int]? {
if #obtainable(iOS eleven.0, *) {
let data = strive! MLMultiArray(shape: [1, 2, 100], dataType: .float32)
let xs = functions.scheme { $0[0] }
let ys = functions.scheme { $0[1] }
let minX = xs.min()!
let maxX = xs.max()!
let minY = ys.min()!
let maxY = ys.max()!
let yShift = ((maxY - minY) / (maxX - minX)) / 2.0
for (i, level) in functions.enumerated() {
let doubleI = Double(i)
let x = Double((level[0] - minX) / (maxX - minX) - 0.5)
let y = Double((level[1] - minY) / (maxX - minX) - yShift)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 0), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: x)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 1), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: y)
}
} else {
return nil
}
}
In the end, I instantiate and whisk the model. _1 and _27 are the very sad names that the input and output layers were assigned someplace alongside the technique. You may per chance per chance click on the mlmodel file within the sidebar to gain out what your names are.
import CoreML
func ruin up(functions: [[Float32]]) -> [Int]? {
if #obtainable(iOS eleven.0, *) {
let data = strive! MLMultiArray(shape: [1, 2, 100], dataType: .float32)
let xs = functions.scheme { $0[0] }
let ys = functions.scheme { $0[1] }
let minX = xs.min()!
let maxX = xs.max()!
let minY = ys.min()!
let maxY = ys.max()!
let yShift = ((maxY - minY) / (maxX - minX)) / 2.0
for (i, level) in functions.enumerated() {
let doubleI = Double(i)
let x = Double((level[0] - minX) / (maxX - minX) - 0.5)
let y = Double((level[1] - minY) / (maxX - minX) - yShift)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 0), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: x)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 1), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: y)
}
let model = SplitModel()
let prediction = strive! model.prediction(_1: data)._27
} else {
return nil
}
}
I even have some predictions! All I want to end is convert the probabilities correct into a list of indices the set apart the probability is larger than 50%.
import CoreML
func ruin up(functions: [[Float32]]) -> [Int]? {
if #obtainable(iOS eleven.0, *) {
let data = strive! MLMultiArray(shape: [1, 2, 100], dataType: .float32)
let xs = functions.scheme { $0[0] }
let ys = functions.scheme { $0[1] }
let minX = xs.min()!
let maxX = xs.max()!
let minY = ys.min()!
let maxY = ys.max()!
let yShift = ((maxY - minY) / (maxX - minX)) / 2.0
for (i, level) in functions.enumerated() {
let doubleI = Double(i)
let x = Double((level[0] - minX) / (maxX - minX) - 0.5)
let y = Double((level[1] - minY) / (maxX - minX) - yShift)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 0), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: x)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 1), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: y)
}
let model = SplitModel()
let prediction = strive! model.prediction(_1: data)._27
var indices: [Int] = []
for (index, prob) in prediction {
if prob > 0.5 && index < functions.count - 1 {
indices.append(Int(index))
}
}
return indices.sorted()
} else {
return nil
}
}
React Native
If this were an completely native app, I could per chance well be performed. But my app is written in React Native, and I needed in an effort to call this neural network from my UI code. Just a few more steps then.
First, I wrapped my characteristic interior a category, and made obvious it became callable from Plot-C.
import CoreML
@objc(Shatter up)
class Shatter up: NSObject {
@objc(ruin up:)
func ruin up(functions: [[Float32]]) -> [Int]? {
if #obtainable(iOS eleven.0, *) {
let data = strive! MLMultiArray(shape: [1, 2, 100], dataType: .float32)
let xs = functions.scheme { $0[0] }
let ys = functions.scheme { $0[1] }
let minX = xs.min()!
let maxX = xs.max()!
let minY = ys.min()!
let maxY = ys.max()!
let yShift = ((maxY - minY) / (maxX - minX)) / 2.0
for (i, level) in functions.enumerated() {
let doubleI = Double(i)
let x = Double((level[0] - minX) / (maxX - minX) - 0.5)
let y = Double((level[1] - minY) / (maxX - minX) - yShift)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 0), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: x)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 1), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: y)
}
let model = SplitModel()
let prediction = strive! model.prediction(_1: data)._27
var indices: [Int] = []
for (index, prob) in prediction {
if prob > 0.5 && index < functions.count - 1 {
indices.append(Int(index))
}
}
return indices.sorted()
}
} else {
return nil
}
}
Then, as an different of returning the output, I made it take a React Native callback.
import CoreML
@objc(Shatter up)
class Shatter up: NSObject {
@objc(ruin up:callback:)
func ruin up(functions: [[Float32]], callback: RCTResponseSenderBlock) {
if #obtainable(iOS eleven.0, *) {
let data = strive! MLMultiArray(shape: [1, 2, 100], dataType: .float32)
let xs = functions.scheme { $0[0] }
let ys = functions.scheme { $0[1] }
let minX = xs.min()!
let maxX = xs.max()!
let minY = ys.min()!
let maxY = ys.max()!
let yShift = ((maxY - minY) / (maxX - minX)) / 2.0
for (i, level) in functions.enumerated() {
let doubleI = Double(i)
let x = Double((level[0] - minX) / (maxX - minX) - 0.5)
let y = Double((level[1] - minY) / (maxX - minX) - yShift)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 0), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: x)
data[[NSNumber(floatLiteral: 0), NSNumber(floatLiteral: 1), NSNumber(floatLiteral: doubleI)]] = NSNumber(floatLiteral: y)
}
let model = SplitModel()
let prediction = strive! model.prediction(_1: data)._27
var indices: [Int] = []
for (index, prob) in prediction {
if prob > 0.5 && index < functions.count - 1 {
indices.append(Int(index))
}
}
callback([NSNull(), indices.sorted()])
} else {
callback([NSNull(), NSNull()])
}
}
}
In the end, I wrote the runt Plot-C wrapper required:
#import Oh, one thing more. React Native doesn’t know easy solutions to convert three-dimensional arrays, so I had to educate it:
#import With all this out of the formulation, calling into CoreML from the JavaScript UI code is easy:
import {NativeModules} from 'react-native';
const {Shatter up} = NativeModules;
Shatter up.ruin up(functions, (err, splits) => {
if (err) return;
});
And with that, the app is ready for App Retailer review!
Remaining Phrases
Closing the Loop
I’m quite contented with how the neural network is performing in manufacturing. It’s now not pleasurable, nonetheless the chilly thing is that it will pick bettering without me having to jot down any more code. All it wants is more data. In some unspecified time in the future I am hoping to originate a plan for customers to post their delight in examples to the coaching position, and thus completely shut the feedback loop of constant progress.
Your Flip
I am hoping you liked this end-to-end walkthrough of how I took a neural network the full formulation from belief to App Retailer. I lined plenty, so I am hoping you chanced on designate in as a minimum functions of it.
I am hoping this inspires you to initiate sprinkling neural nets into your apps as effectively, although you happen to’re working on something less ambitious than digital assistants or self-using cars. I will’t wait to head attempting for what ingenious uses you will construct of neural networks!
Calls to Inch!
Take one. Or two. Or all. I don’t care. You end you:
You may per chance per chance hire me as a advertising and marketing and marketing and marketing consultant. I specialise in React, React Native, and ML work.
Because of the Casey Muller, Ana Muller, Beau Hartshorne, Giuseppe Attardi, and Maria Simi for reading drafts of this.
Learn Extra
Commentaires récents